Most research labs aren't ready for AI. Not because they lack access to the latest and greatest AI tools, but because their projects and data aren't structured enough for any tool, intelligent or otherwise, to make sense of it.

Every lab software company is talking about AI right now. AI native ELNs. Experiment design powered by LLMs. Automated data capture. OpenAI just acquired Torch to embed itself in medical workflows. Anthropic acquired Coefficient Bio to build biological research models with automated experimentation baked in. The race to bring AI into the lab is accelerating, and many companies worry they are being left behind.
I'm not here to argue against any of that. I don't think anyone could say that AI is not already changing how research gets done. However, I've spent enough time inside research organizations to know that adding AI on top of disorganized data just produces more chaos. If the disparate parts of your data ecosystem were never captured, or sit somewhere no one else can reach, an AI agent has nothing to find or connect either.
Why data fragmentation is the real problem
OpenAI recently published a report on AI in the life sciences that borrows a term, the "Great Endarkenment," coined by the philosopher Elijah Millgram in his 2015 book of the same name. Their argument is that scientific fields have fragmented into such narrow specialties, with such incompatible vocabularies and siloed knowledge, that no single person, or system, can track the full picture anymore. Drug development now costs $2.6 billion per approval with a 7.9% success rate. Eroom's Law shows that ROI has dropped by a factor of 80 since 1950. A lot of AI vendors are now pitching their solutions as a means of reversing this trend.
The deeper problem isn't the volume of knowledge piling up, it's the connective tissue between specialties thinning out.
A recent example came from pure mathematics. In May, an OpenAI model resolved the planar unit distance problem, a question Paul Erdős posed in 1946 that had gone unsolved for 80 years. A system that isn't locked into one field's vocabulary found the bridge decades of focused human effort had missed. That is the real edge AI has against the Endarkenment: not raw intelligence, but the ability to work across silos that specialization keeps apart.
And that same fragmentation plays out inside individual labs every day.
A scientist or postdoc runs an experiment and saves the results in a folder structure only they understand. A team member leaves and takes their institutional memory with them. A PI asks whether anyone has tried a particular condition before, and three people spend an afternoon searching shared drives and old notebooks before concluding "probably not," even though someone did, two years ago, and the negative result would have saved the team months.
Polymer scientist Brenden Ferland recently gave this failure mode a clever name: "The Squid Problem." When turnover meets paper notebooks (or poorly structured digital ones), experiments vanish into the past and new team members unknowingly repeat years of prior work. Ferland loaded four years of his own research notes into an AI model and it surfaced an experiment he'd completely forgotten running. The knowledge was always there. It just wasn't findable.
This isn't a problem that needs AI. This is a problem that needs better lab data management.

How disorganized lab data undermines research productivity
A recent study of 150 lab professionals across the US and Europe found that 65% of scientists have repeated experiments because the results from a previous run weren't findable or reusable. Not because the experiment failed, but because the record of it was effectively lost.
Meanwhile, 77% of scientists are already using public AI tools for lab work. Nearly half are doing it through personal accounts, outside any organizational visibility. Labs have entered what the study calls the "Shadow AI" stage. Researchers are adopting AI on their own because their official tools aren't getting the job done, and they're doing it in ways their institutions can't see, govern, or learn from.
And the labs that haven't adopted AI yet? Most of them are still in what the same researchers call the "Passive" stage, where the ELN is a digital filing cabinet, experiments go in but insights rarely come out, and the notebook exists to satisfy compliance rather than accelerate research.
Adding AI to a passive lab doesn't make it an active lab, it just makes it a faster passive lab.
Why AI in the lab requires structured experiment tracking
A lot of people have started referring to AI as their "second brain" and using it for structuring decision making in the lab: a protocol reviewer, a failure analyst, a way to reduce ambiguity and expose hidden variables. This is clearly the direction that AI adoption is going (AI as a thought partner), but the scientists getting the most out of AI are the ones who are already good at structuring their work.
That's the catch: AI as a second brain only works if your first brain is organized.
If your experiments aren't tracked in a way that's searchable, AI can't surface them or identify patterns across them. If your project decisions aren't documented, AI can't help you trace why a decision was made or a process abandoned. If your results live in spreadsheets, email threads, and someone's personal Google Drive, the most sophisticated language model in the world can't connect dots that were never drawn.
Ferland's Squid Problem looks at first like the opposite of my argument: the data was a mess, and AI made sense of it anyway. But look at what he had. Four complete years of his own notes, disorganized but not missing, that he could hand to the model in full. The AI gave him findability, and that's only half of what structure means. The other half is whether the record exists at all, and whether anyone but the author can reach it. That's the half that fails in most labs: the experiment nobody logged, the notebook that left with a departing postdoc, the results in a personal Google Drive no one else can open. AI never gets to read any of those. Ferland could feed it everything; most teams can't, because the everything is gone or scattered. The technology isn't the bottleneck, the data infrastructure is.
The scientists who will benefit most from AI in the lab will be the ones who've already solved the lab data management problem and have their experiments, results, and decisions in a system that's structured, findable, and reusable. Everyone else will get autocomplete for chaos.
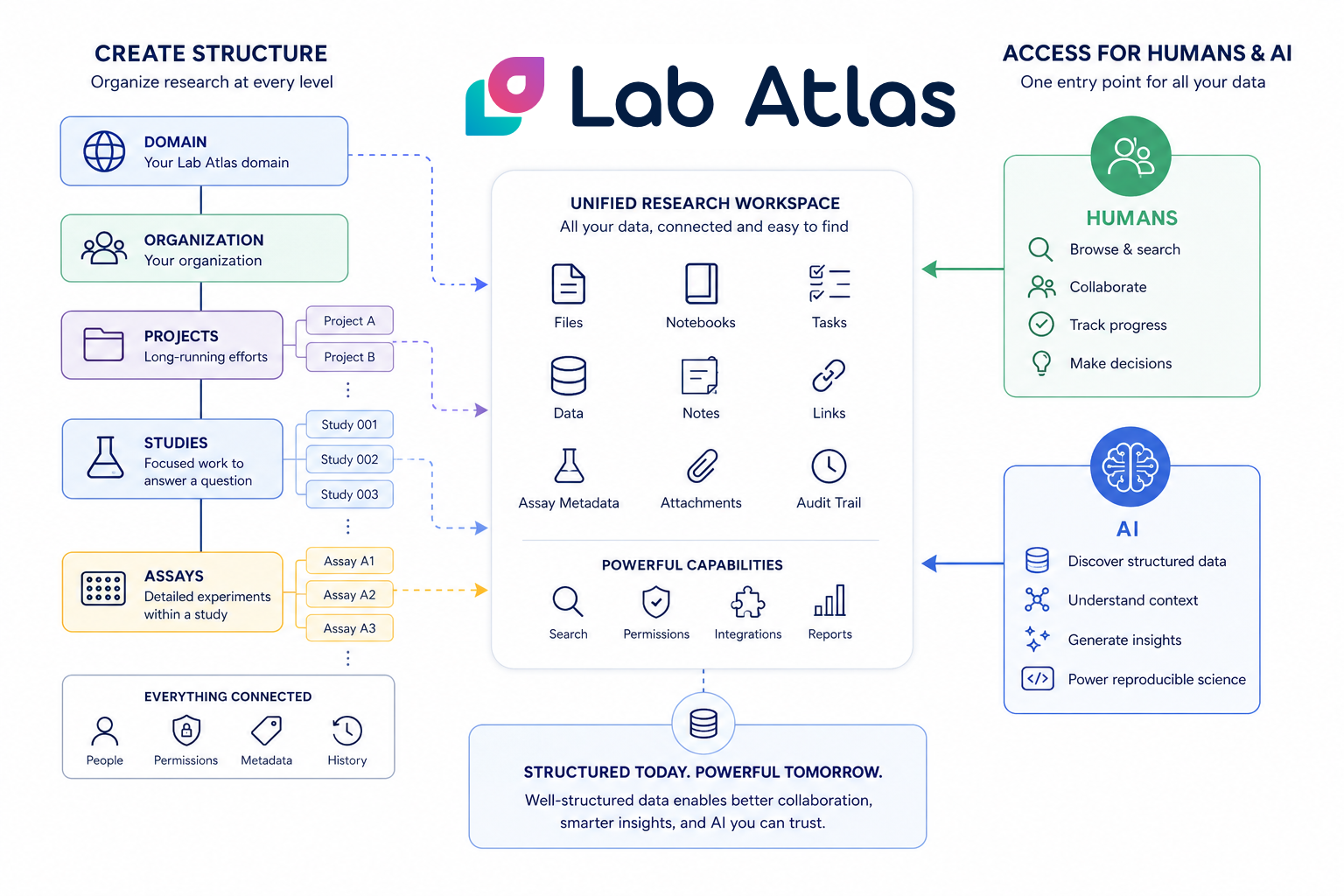
Lab data management before artificial intelligence
I think a lot about the order of operations here, because it matters for how labs should be spending their time and money right now.
The AI native ELN pitch is seductive: skip the boring infrastructure work, jump straight to the future. But 81% of scientists say they'll only rely on AI suggestions if they can review the underlying evidence. Trust requires transparency, and transparency requires structure. You can't review the evidence if it was never captured properly in the first place.
The labs that will get the most out of AI, whenever it arrives in a form they trust, are the ones investing in research data management today. Not structure for structure's sake, but the kind that makes good data practices the path of least resistance: organized projects, tracked experiments, and findable results. The unsexy foundation that everything else depends on.
That's what we built Lab Atlas to do: not to be the AI layer on top of your research, but to be the infrastructure that makes an AI layer (or any kind of collaboration, reuse, or institutional memory) actually possible. We provide a structured project hierarchy, consistent record labeling, file & notebook access, and a full history of your team's work. Not only is this rich data infrastructure accessible to humans, but with our existing API and forthcoming MCP server for AI agents, it becomes equally accessible to machines.
The labs that get this right won't just be ready for AI. They'll already be working better without it, and they'll get more out of it than anyone else when they use it.